── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggplot2)library(dplyr)library(plotly)
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
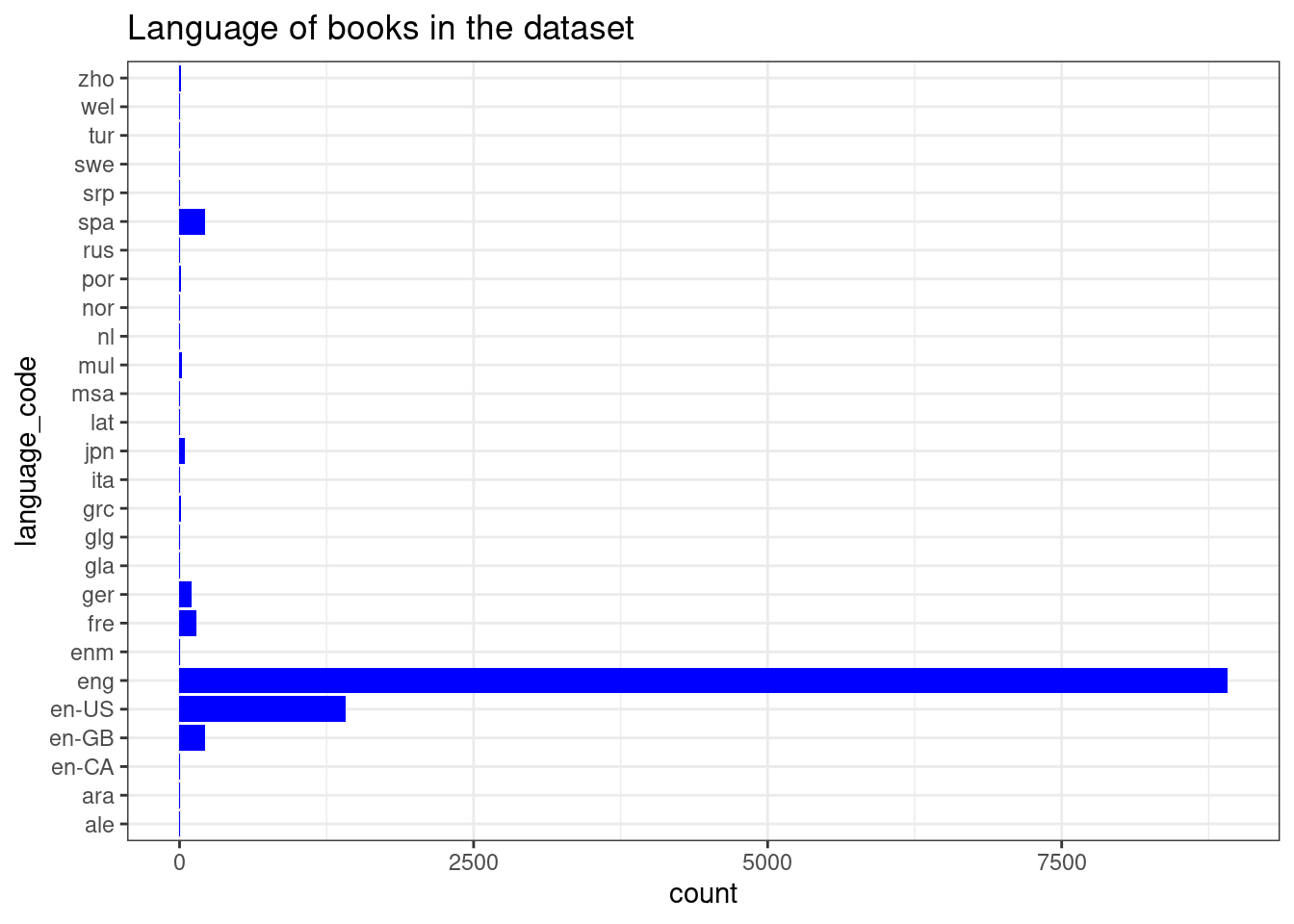
Looking at the dataset
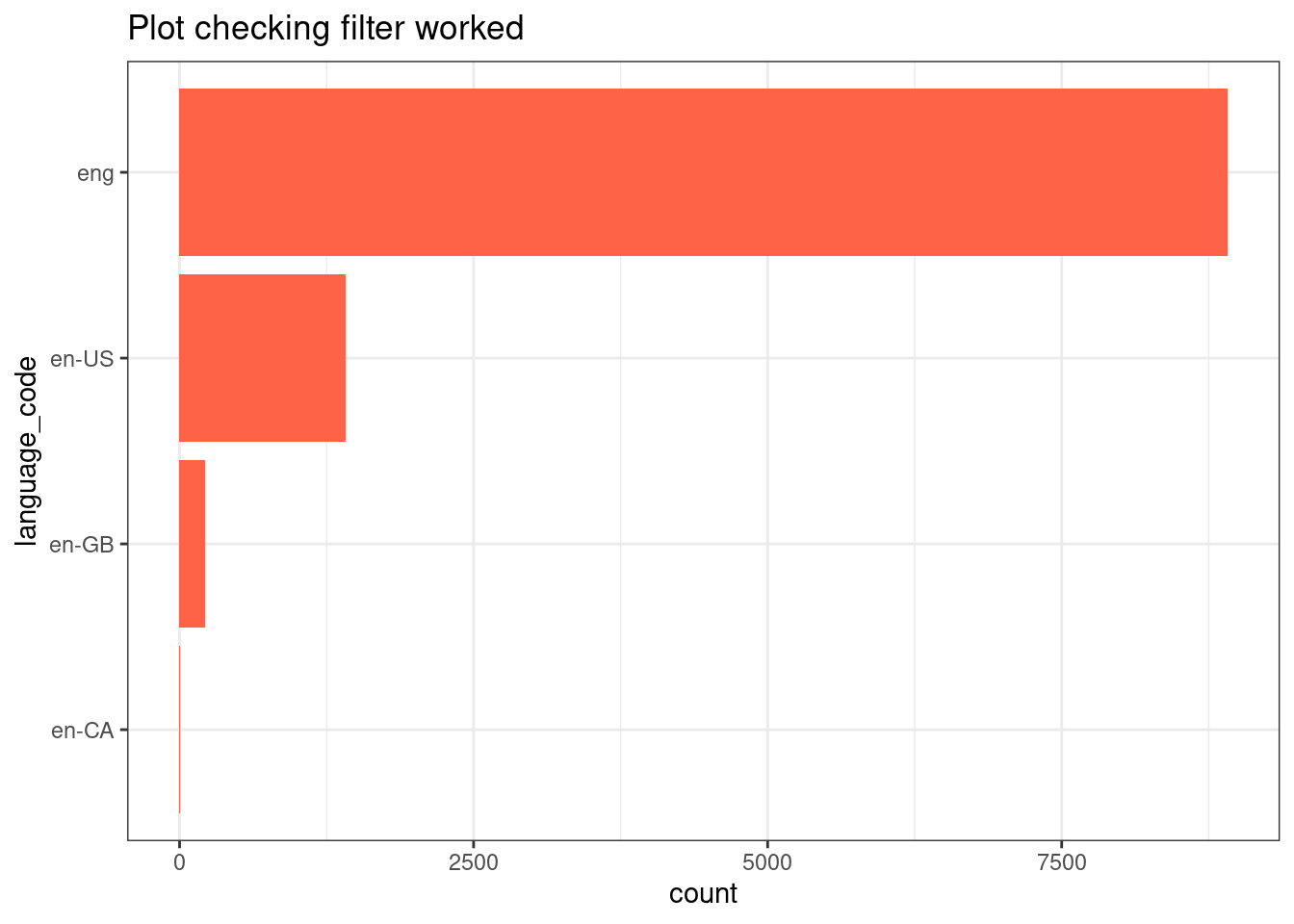
ggplot(books, aes(y = language_code)) +geom_bar(fill ="blue") +theme_bw()+labs(title ="Language of books in the dataset")
We have found that the datasets countain books from different languages.
[1] "The lowest rating book is Citizen Girl by Emma McLaughlin/Nicola Kraus"
people <- books_eng_cleaned %>%filter(ratings_count ==max(ratings_count))print(paste("The book that most people hate is", people$title, "by", people$authors))
[1] "The book that most people hate is Twilight (Twilight #1) by Stephenie Meyer"
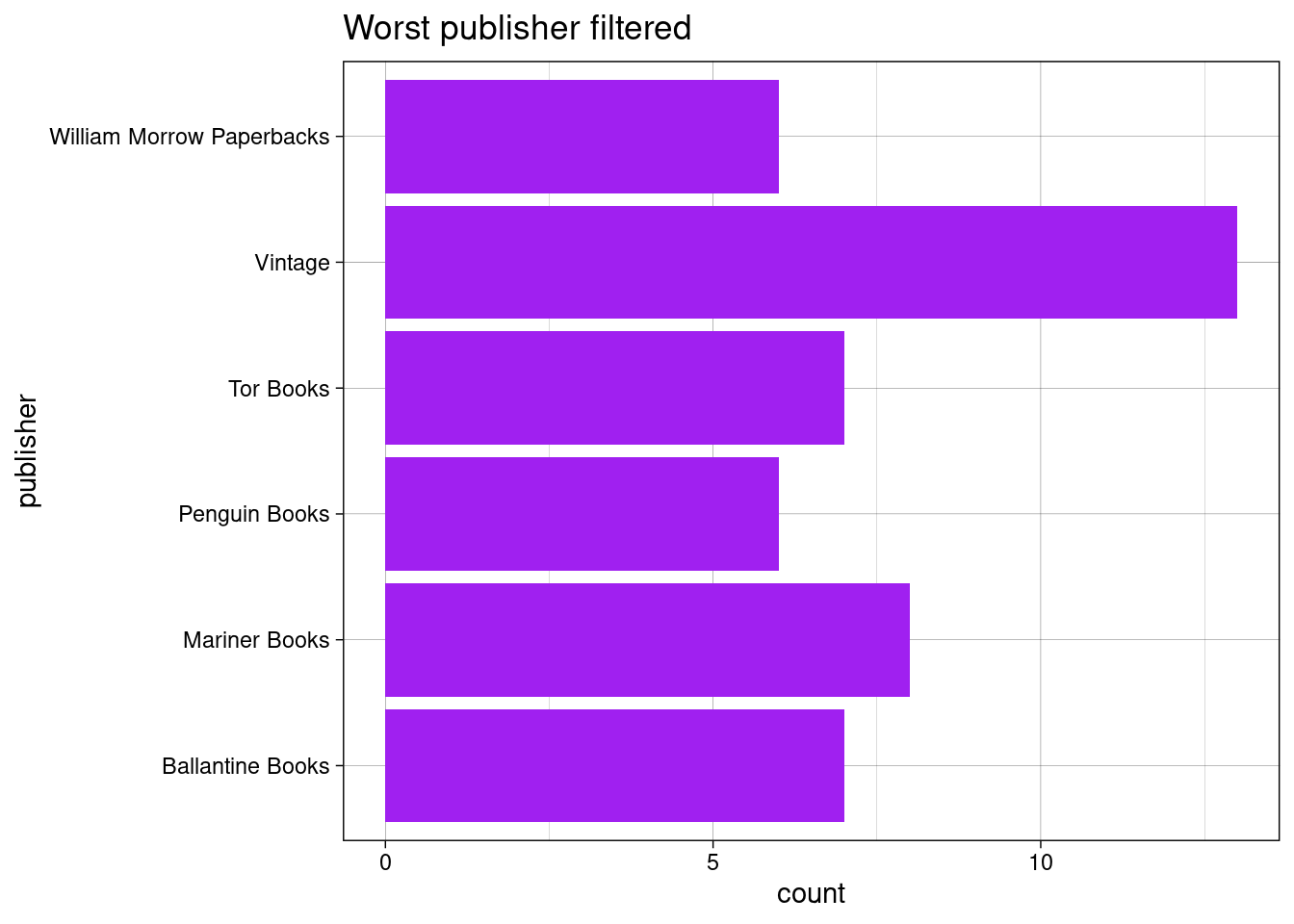
And to find out which publisher got the most amount of bad books…